
出品|搜狐科技
作者|郑松毅
编辑|杨锦
近日,日本乐天集团高调官宣“日本国内最大规模、性能最强”的AI大模型——Rakuten AI 3.0,宣称其搭载7000亿参数,是日本政府扶持下的“本土AI里程碑”,肩负着“摆脱海外技术依赖”的使命。
然而发布仅不到12小时,该模型就被全球开源社区扒穿——被捧为“日本AI全村希望”的模型,内核竟然照搬中国DeepSeek V3。所谓“自研”不过是换皮微调,更涉嫌刻意虚假宣传,一场闹剧迅速演变为AI圈年度最大丑闻。
12小时破防的“自研神话”
乐天对Rakuten AI 3.0的宣传堪称“铺天盖地”。官方介绍,该模型采用混合专家(MoE)架构,总参数量约7000亿,在日语文化历史知识、研究生级推理、竞技数学等领域的测试成绩远超GPT-4o等前沿模型,是“打破海外AI垄断的重大成果”。
作为日本政府重点扶持对象,这款模型还获得了特殊补贴,乐天首席AI官Ting Cai更是将其称为“数据工程与创新架构的规模化杰出结合”,一度被日本媒体奉为“国家队希望之光”。
然而,光环的消退速度极快。
搜狐科技从官方上传至Hugging Face开源平台中的config.json配置文件发现,文件中“architectures”字段写着“DeepseekV3ForCausalLM”,“model_type”字段直接标注“deepseek_v3”,毫无遮掩可言。
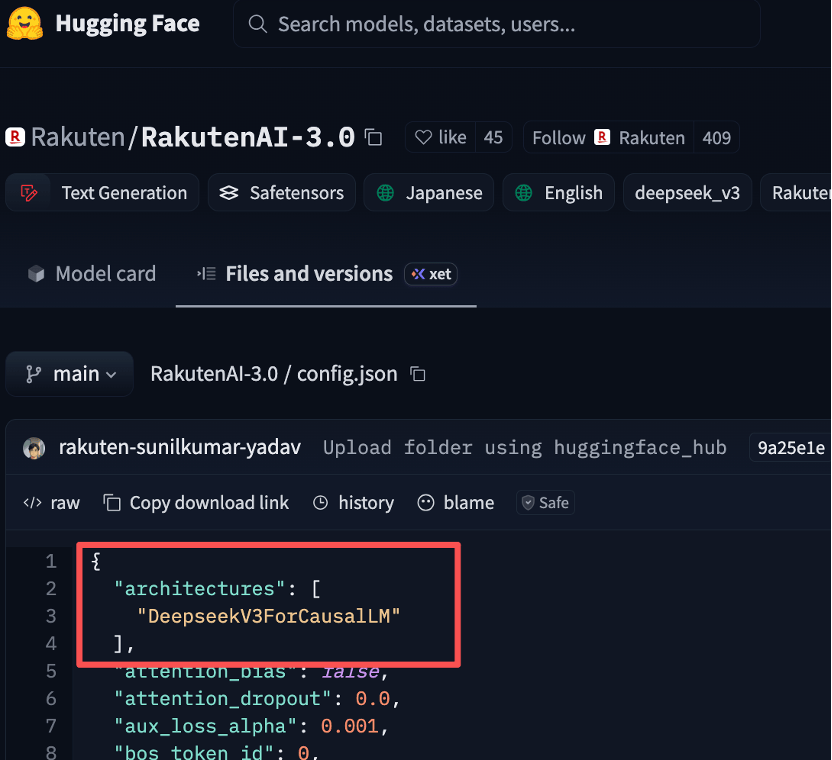
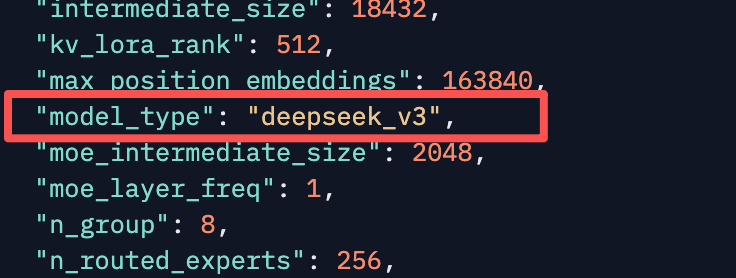
更致命的是,Rakuten AI 3.0的核心参数与DeepSeek V3完全重合:总参数量实为671B,乐天宣传的“7000亿”不过是四舍五入的噱头,甚至MoE架构的设计细节都分毫不差。
有开发者调侃:“这哪里是自研,分明是把DeepSeek V3的内核拿过来,换了个日语皮肤就敢称第一。”
开源不是放任抄袭,律师解读如何合规使用
在AI行业,基于开源模型进行二次开发是常态,DeepSeek V3采用的MIT/Apache 2.0开源协议,更是业内最宽松的许可之一,仅要求使用者保留原创方版权声明,即可自由商用、修改。
乐天的争议,从来不是“使用开源模型”,而是“刻意隐瞒”的恶劣操作,彻底触碰了开源伦理与商业诚信的底线。
也难怪有日本网友怒批:“我们缴纳的税金,不是用来让企业做‘换皮游戏’的。”
更令人不齿的是,DeepSeek V3的开源协议明确要求使用者保留版权声明与许可证文件,乐天却在初始上传模型时刻意删除包含DeepSeek信息的MIT许可证文件,甚至偷偷将协议替换为自身的Apache 2.0版本,试图彻底抹除中国技术的痕迹,直到被开源社区实锤后,才慌忙补传NOTICE文件、补上DeepSeek的版权信息。
与此同时,乐天在所有官方宣传中全程未提及“DeepSeek”三字,仅用“融合开源社区精华”一笔带过。
细心网友在模型实测中也发现端倪,这款“日本最强AI”在回答相关问题时,舆论立场竟明显偏向中国,坐实其“中国内核”的身份。评论区有网友无奈调侃:“我们以为的本土之光,连立场都站不对。”
不少开发者表示:“开源的本质是共享与透明,不是拿来欺世盗名。乐天删除许可证的行为,比套壳更恶劣,破坏的是整个开源生态的信任。”
有AI行业分析师指出,此次事件侧面印证了中国开源大模型的实力——DeepSeek V3能被日本巨头直接采用,说明其架构、性能已达到全球顶级水平,“中国一开源,日本就自研”的背后,是对中国AI技术的认可。
开源中国董事长马越也向搜狐科技直言,“这是好事,开源就不怕被抄,说明了国内开源模型的实力。开源的目的就是要从竞争的角度去分那些闭源的市场,如果开源后没人用,没人抄,那开源有什么意义呢?”
不少人仍有疑问,该如何合规使用开源模型?
隆安律所全国合规委副主任陈焕向搜狐科技介绍,首先必须保留原始许可证文件,这是最基本的要求;其次,需要在产品文档中详细说明技术栈——包括基础模型、微调数据、微调方法等信息;最后,建立企业内部的开源合规审查流程,确保每一个基于开源模型开发的产品都经过充分的合规检查。
值得注意的是,乐天事件并非个例。据报道,日本企业开发的前十大AI模型中,有6个均以DeepSeek或中国通义千问为底座进行二次开发,只是其他企业均坦诚标注了来源,而乐天选择了隐瞒。

